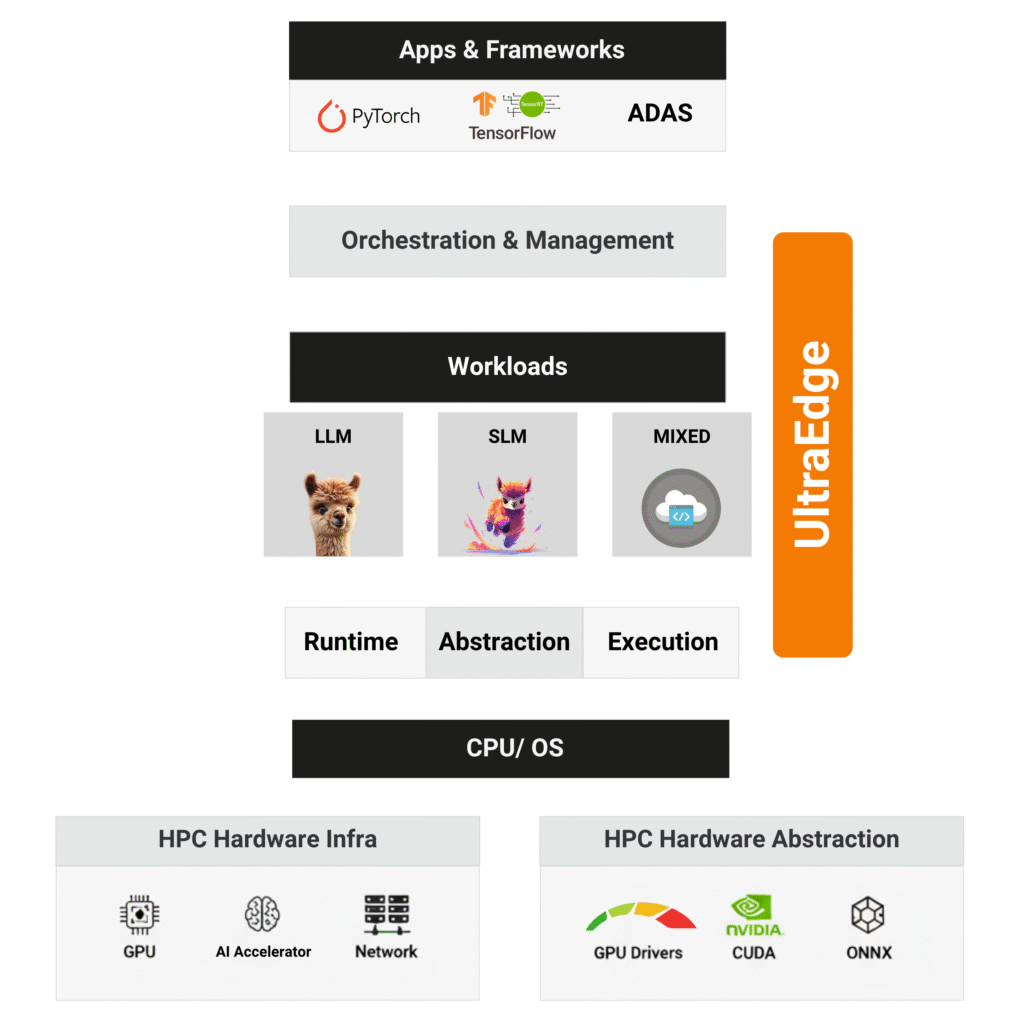
UltraEdge anchors execution on CPUs while orchestrating GPUs and accelerators — turning fragmented hardware into a unified high-performance layer.
“UltraEdge in action — packaging and executing workloads instantly with the MicroPac CLI.”
The Functional Architecture of UltraEdge
UltraEdge delivers its capabilities through modular Stacks. Each Stack combines packaging, runtimes, and developer tooling - optimized for its workload type but unified inside one execution fabric.
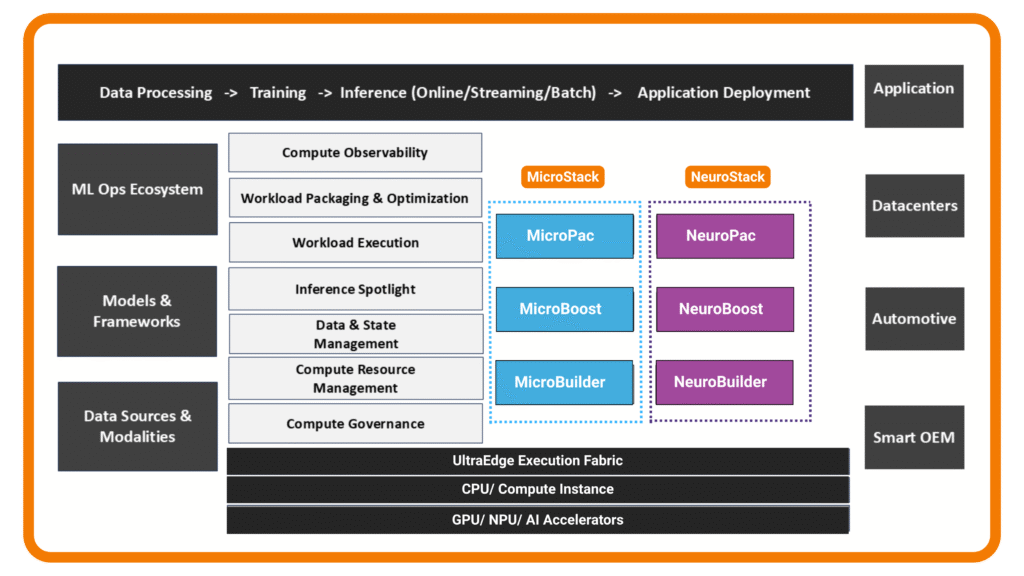
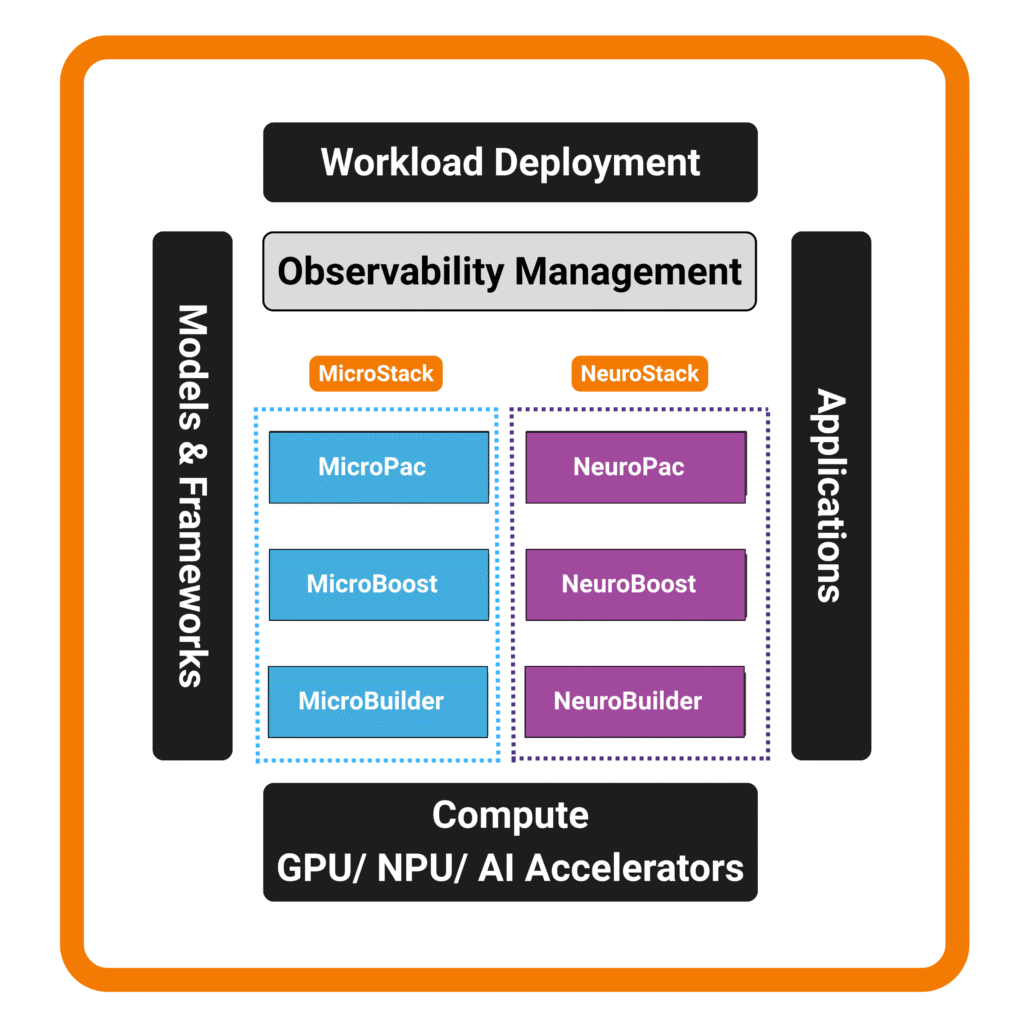
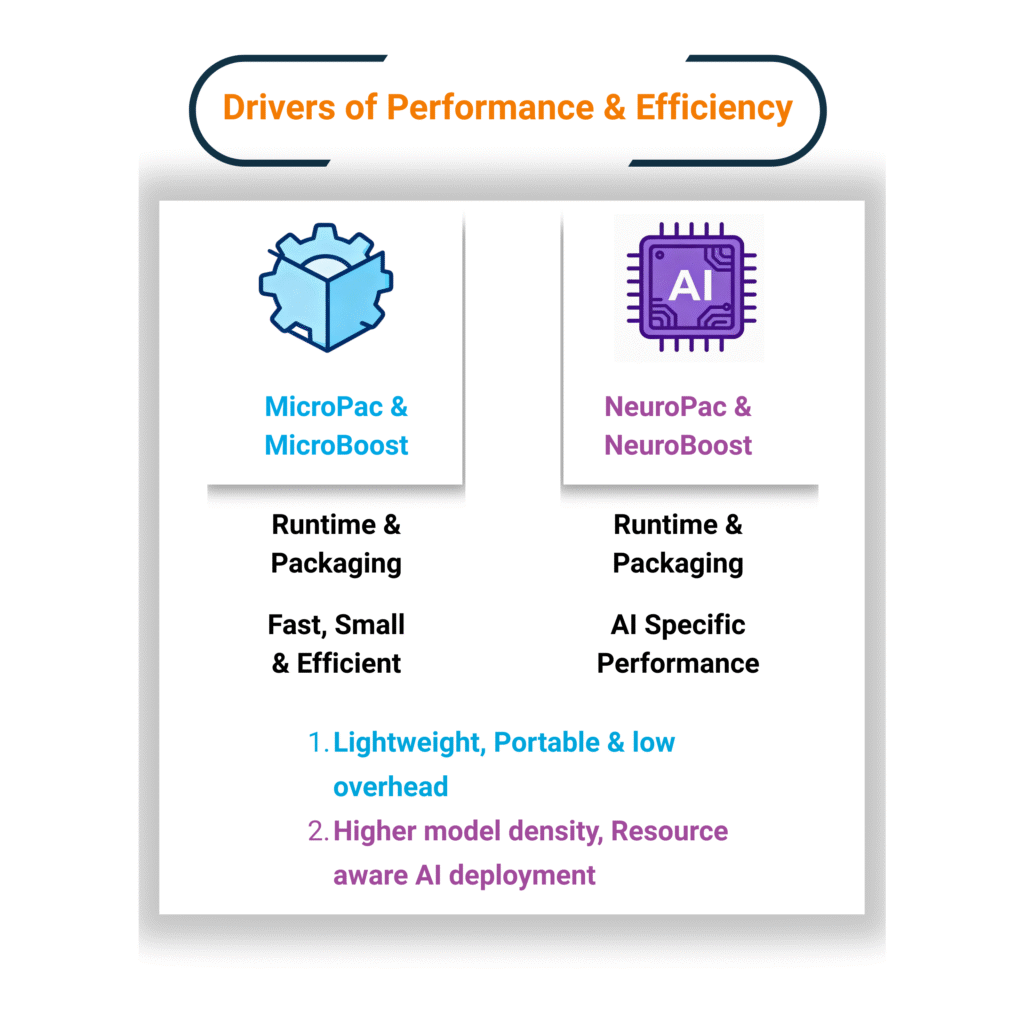
Deploy, Execute, and Scale with Confidence
UltraEdge integrates seamlessly into enterprise and hyperscale environments, enabling deterministic execution and fleet-wide scalability.
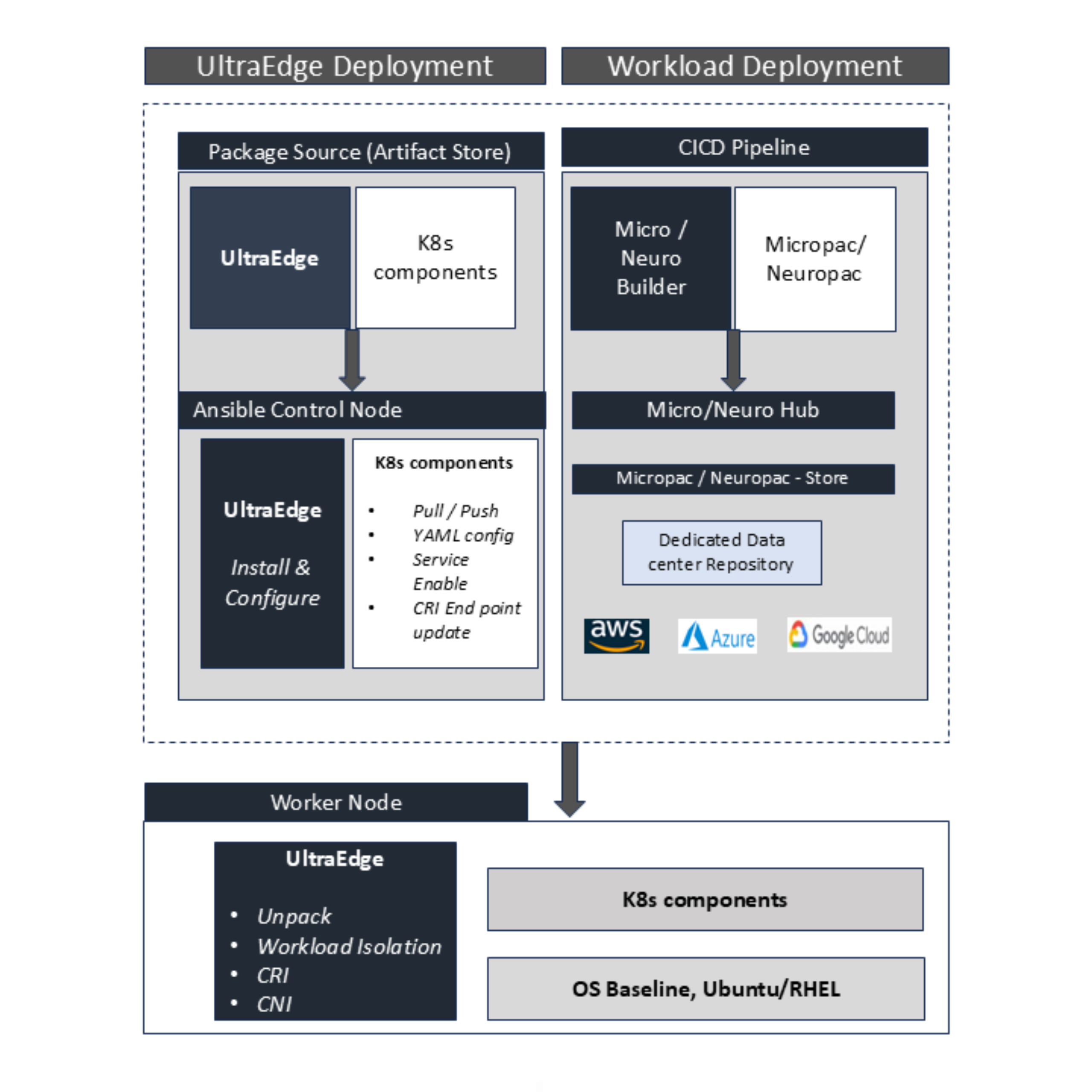
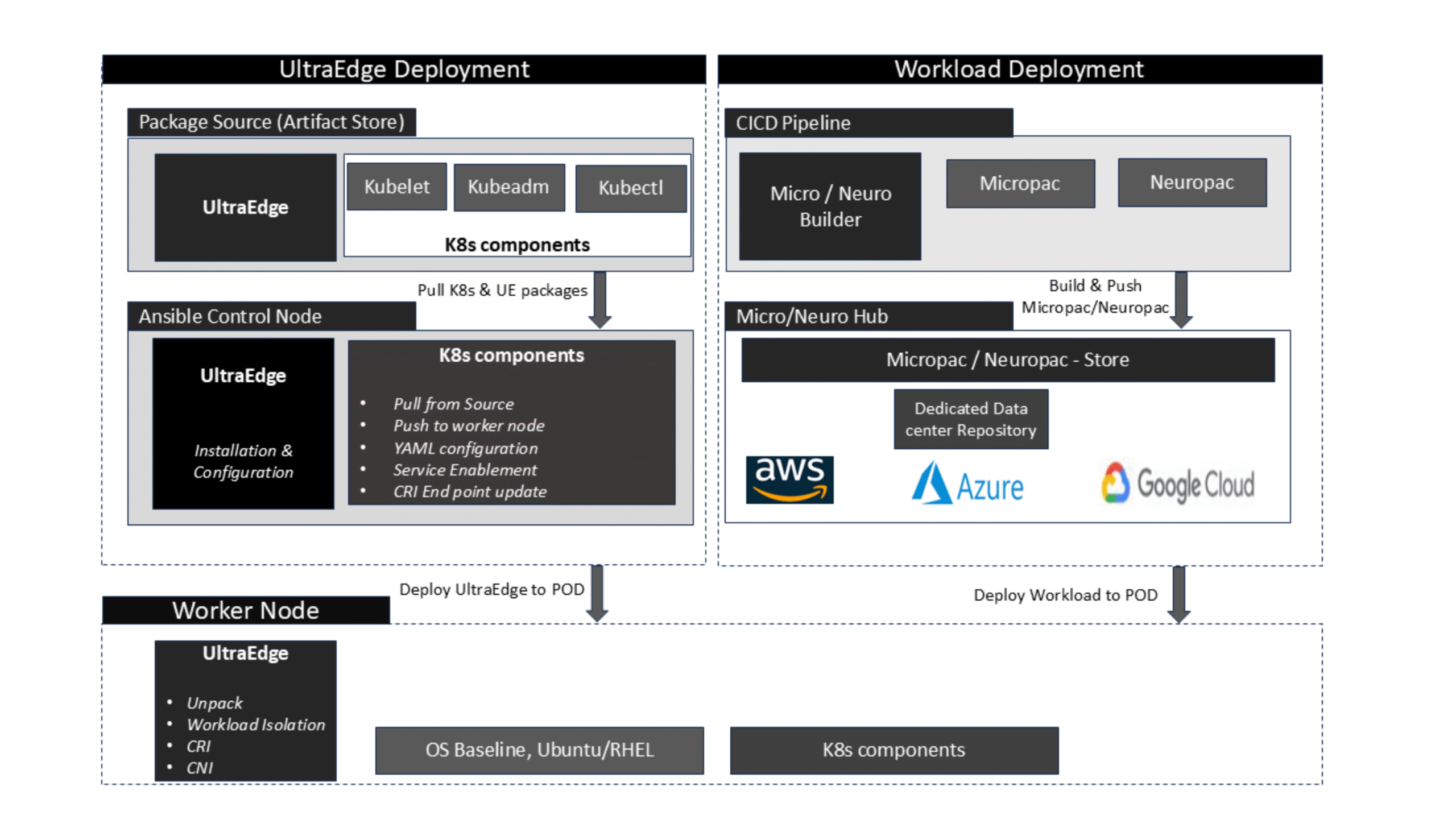
Deploy workloads deterministically, execute them at peak efficiency, and scale seamlessly across heterogeneous compute.
Testimonials
Testimonials, as authentic endorsements from satisfied customers, serve as potent social proof, significantly inspiring trust in potential consumers.

Testimonials, as authentic endorsements from satisfied customers, serve as potent social proof, significantly inspiring trust in potential consumers.

Testimonials, as authentic endorsements from satisfied customers, serve as potent social proof, significantly inspiring trust in potential consumers.
Optimize your workloads. Maximize your performance.
Let’s discuss how TinkerBloX can streamline your AI and mixed workload execution — from training clusters to real-time inference.